Dit blog is een onderdeel van EVODISKU WAT IS DE BEDOELING EN WAAR STAAT DIT BLOG VOOR
****Wie meent dat alles inmiddels wel over de evolutietheorie gezegd is en dat de discussie gesloten kan worden, ziet over het hoofd dat de wetenschap niet stil staat.
***Wie meent dat inmiddels het creationisme definitief het pleit heeft verloren en dat de discussie gesloten kan worden , ziet over het hoofd dat het "creationisme" is geevolueerd ( en zal evolueren ) in nieuwere mimicrytische vormen( meme-complexen ) zoals bijvoorbeeld het ID(C)
***Dit blog is speciaal opgezet om de aktualiteit binnen het evolutie-creationisme debat te volgen en van kommentaren te voorzien ... waartoe de lezers zijn uitgenodigd bij te dragen ...
Let echter wél op het volgende :
"Je bent een rund als je hier met religie stunt " ....
22-08-2007
Wetenschappelijke parate Kennis neemt af bij jongeren ?
De Belg getest - resultaten peiling wetenschappelijke kennis
Vorig jaar hield Eos in juni een enquete over het "geloof , Intelligent design ( de "geleerde " vorm van het creationisme) en de evolutieleer" ,en zoals dat door de belgische academici ( zoawel zogenaamde alfa ( geest ) als beta ( natuur-)wetenschappers : om de "hollandsche "terminologie te gebruiken ) wordt/werd ingeschat ...(1)
De jongste peiling die Eos in 2007 hield onder de Belgische bevolking, gaat over : Het kennisniveau van wetenschap en technologie bij de Belgen ( het daaruit noodzakelijk volgende grotere begrip voor de werkelijkheid die ons allen omringd werd niet onderzocht ? ?? ) IK heb zelf het artikel nog NIET i n handen gehad of gelezen maar ik stel me nu al een paar vragen en wil zelfs al een paar bemerkingen plaatsen ... ( uiteraard moet de geldigheid , representatieviteit en precisie van deze enquete ook nog worden nagechekt / het nummer verschijnt pas ( ten laatste ) in september .. ) *
Maar Enkele conclusie van dat laatste onderzoekje van Eos zijn al vermeld op het vrt -nieuws en aangekondigd op de eigen site van het blad http://www.eos.be/homenl.asp?qI=L #3
Samengevat komt het neer op ;
Er valt een bedroevende achteruitgang van de wetenschappelijk kennis-niveaus te konstaten bij jongeren tussen 18 en 24 jaar Dat niveau ligt beduidend lager dan bij de oudere generaties .
OPGEMERKT dient te worden dat de oudere generaties altijd vinden dat de kennis van de jeugd veel minder is dan in de hun tijd
Regus Patoff - 22/08/2007 ''Bij vragen over basiskennis halen de Belgen gemiddeld 75 procent. Dat is een goed Europees gemiddelde, maar de ouderen scoren opvallend beter dan jongeren. ' die volgens dit rapport slechts 52 % halen ...
Bij de vraag over de aarde die rond de zon draait, scoren de 65-plussers het beste. Een op de drie jongeren weet niet eens dat de aarde rond de zon draait', luidt het. '' ------
Nog enkele opmerkelijke resultaten:
* de meerderheid van de Belgen weet niet dat homeopathie geen wetenschappelijk aanvaarde geneeswijze is, * en het gat in de ozonlaag situeren de meesten boven de noordpool
Volgens wetenschapsfilosoof Gustaaf Cornelis van de Vrije Universiteit Brussel ligt dit gedeeltelijk aan het onderwijs. "In het onderwijs wordt minder aandacht gegeven aan feitenkennis. Bovendien is het aanbod aan toegankelijke informatie veel ruimer geworden ...." (Denk ook aan het internet : jongeren surfen veelvuldig maar hebben ( nog niet ) de nodige kritische vaardigheden om de morosofen , idiotieen , de pseudo en junk kennes en het proselitisme eruit te filteren ...etc ... Bovendien gaan ze op zoek naar "leuke" info ) Er is dus wel degelijk nood aan kritische vorming maar "Toch zouden de jongeren die basiskennis wel moeten hebben om zich een beeld van de wereld te kunnen vormen. Kijk maar naar de discussie over creationisme ( noot : vooral ook naar de vele internet desinformatie die wordt gespuid door allerlei sektaire pseudo's , dilettanten en orakelende irrationalisten )" vindt Cornelis....
Over gezondheid weten Belgen wel tamelijk veel, zo schrijft EOS nog.
De achteruitgang van parate basiskennis in de beta-vakken , (het toenemend wetenschappelijk analfabetisme ? , de ( in het algemeen) volslagen onbekendheid met de wetenchappelijke methodiek en kennisleer ...) : het voortwoekerend bijgeloof en het onuitroeibare abracadabra en verhaaltjes vertellen ,( ook in de vorm van reeds lang aanwezig alternatief para - gedoe en andere oude " esosterische " en " heilige " kennis )zijn de diepere oorzaken van een dreigende afkalving en van een verminderd aanbod van goed opgeleide krachten bij het broodnodige voortzetten van het wetenschappelijk bedrijf en uitbouw van de ( door sommige politici geroemde maar tegengewerkte ) "kennis-ekonomie" ..,en van een groeiende populistsche achterdocht jegens natuurwetenschappen en uitbreiding van pseudo- en junk wetenschappen : de demagogische anti-science bewegingen en de nieuwe obscurantismen van de (bij)gelovigen ...
Blijkbaar maakt onze maatschappij zich onderhuids op om massaal terug in een soort "nieuwe middelleeuwen" te duiken ? althans voor een gedeelte van de bevolking dreigt een soort " nieuw analfabetisme " ....
P.S. Het zich vrolijk maken over" amerikaanse hilliebillies " enzo , zouden we ook best laten voor wat het is ... er is werk genoeg aan de winkel in ons eigen landje, me dunkt ....
"In Europa wordt er vaak lacherig gedaan over "die onnozele Amerikanen" die zo naïef in Bijbel en bijbelaars geloven, maar dat is goedkope kritiek. Jawel, het Christelijke fundamentalisme is verder gevorderd in Amerika dan in Europa. Het rukt echter ook langzaam maar zeker op in Europa. De Raad van Europa heeft daar nog niet zo lang geleden over gediscussieerd in verband met het zogenaamde Creationisme Ook in Europa zijn er immers steeds meer mensen die geloven dat de wereld ergens tussen zesduizend en tienduizend jaar oud is.
We mogen bovendien niet vergeten dat er veel meer religieuze scholen zijn in Europa dan in Amerika. Godsdienst stimuleert kritiekloos denken en blind geloof in een autoriteit, dat is de vruchtbare grond waarop figuren als bijvoorbeeld Benny Hinn of machtgeile politiekers met autoritaire neigingen gedijen, tot meerdere eer en glorie van henzelf. Het lijkt dus niet meer dan logisch dat het Christelijk fundamentalisme ( evenals het moslimfundamentalisme en creationisme ) zich ook in Europa verder zal doorzetten, en mogelijk nog virulenter ( en in het geval van de islamitische creationisten ala Harun Yahyah , acuter en betekenisvoller ) dan in Amerika...."
* ondertussen( 23 augustus ) zijn de eerste bedenkingen over de ENQUETE binnen ; (in De Standaard ) -->Veel te kleine niet representatieve steekproef .... vragen die peilen naar het "benoemen" ipv naar begrip en doorzicht ...Quizzers kennis --> Ministers Van Den Broecke en Fientje Moerman
Johan Braeckman heeft ook een paar ad rem opmerkingen ingezonden naar de opiniebladzijde van " De Morgen "
Zie verder hierover --> de eerste twee toevoegingen in "reacties "
....Uit een onderzoek onder Vlaamse wetenschappers, wat in opdracht van EOS is uitgevoerd, naar voren is gekomen dat maar liefst 1 op de 7 wetenschappers Intelligent Design als een reëel alternatief voor de evolutietheorie houdt. Dat is maar liefst 5% van alle wetenschappers in Vlaanderen. "Dat er in België weinig over Intelligent Design wordt geschreven en gediscussieerd, betekent niet dat het de wetenschappers koud laat", aldus de website.
'Wat mij meer verontrust is het feit dat als je de cijfers van de antwoorden 'ja' en 'geen mening' optelt, je aan bijna 20 procent komt,' zegt prof. Johan Braeckman, hoogleraar wijsbegeerte aan de Universiteit Gent. 'Dat betekent dat 1 op de 5 academici niet klaar en duidelijk kan zeggen dat ID complete nonsens is.'
Uit het juni-nummer van EOS 2006 lijkt hieruit Opnieuw naar voren te komen dat Intelligent Design heel langzaam aan een opmars in Europa bezig is...
* En natuurlijk ook de jongste heisa rond het politiek agenda van het creationisme en enkele crhisten democratische eieren ... ( hieronder in vorig bericht )zoals dat woedt op de pagina's van De Standaard en het lezers forum van die krant ...
* Het zou wel eens kunnen dat het Creatonisme in wezen niets anders meer is dan alleen nog maar een middel in de handen van mogelijk manipulerende en politieke intriganten. ( voornamelijk in de betekenis van G. Orwell' s "newspeak" -uitvinders en de (tegenwoordige )junk -wetenschappers /aka " spin-doctors " ... ) Politiek gekuip en gelobby is zeker het enige wat ( ook de sektaire en lobbyende creationisten ) overblijft ... want het creationisme en de ID , ZIJN geen wetenschap Hun wetenschappelijke pretenties zijn kompleet afgevoerd
De enige ( = zeer weinige )ooit geformuleerde wetenschappelijk testbare ondersteuningen van hun leer zijn ( logisch- epistemologisch )foutief bevonden en/ of empirisch proefondervindelijk gefalsifeerd of minstens anders ( en wetenschappelijk consistenter/ legitiemer ) verklaard en/of verklaarbaar dan door de crea's en ID-oten voorgestelde ad hoc hypotheses en mistgordijn- theorieeen .... ) Bovendien hebben creato's en ID-ers nooit echt /eigen (peer reviewed ) wetenschappelijk onderzoek gedaan naar de eigen "zogenaamd" wetenschappelijke ontdekkingen ... Het enige wat ze doen is kritiek leveren op de wetenschap en op zoek gaan naar nog onopgeloste problemen binnen de wetenschap ...Bovendien zeggen ze steeds weer dat ook evolutiewetesnchap ook een " geloof " is en de wetenschap slechts een " mening" over de " waarheid " of op zijn best een zeer beperkte visie ....
22/08/2007 - Joris Vanderaert
Er bestaan verschillende Waarheden. Gewoonlijk geldt, hoe groter de W, hoe minder waarschijnlijk dat men met de waarheid te maken heeft. De wetenschappelijke benadering is en blijft de beste: de wAARHEID met een kleine w, met het besef dat 1. de waarheid op zich niet het doel is van de wetenschap en 2. de w stilaan kan groeien, maar enkel door objectief en controleerbaar onderzoek te doen, niet door prietpraat voor waar aan te nemen.
** Tenslotte neem ik hier het vrij belangrijke stuk van prof Jozef T. Devreese , hoogleraar emeritus ... volledig over Ik denk dat dit de meest verstandige conclusies toelaten die ik de laatste dagen heb mogen lezen ...
Op wetenschappelijk vlak betekenen creationisme en intelligent design geen bedreiging. Hun verstrengeling met de politiek is wel verontrustend, vindt Jozef Devreese die de polemiek door de bril van een natuurkundige bekijkt.
In de Griekse Oudheid streefden de wijsgeren naar een allesomvattend wereldbeeld. Zij stelden zowel de hoe-, de wat- en de waarom-vragen: over vallende stenen maar evenzeer over de ziel. De moderne natuurwetenschap, die ontstond tijdens de renaissance, ontwierp een nieuwe methodiek. Wat- en waarom-vragen werden verbannen. Uitsluitend het hoe van de natuurverschijnselen werd nog onderzocht via een combinatie van experiment en theorie. Theorie wordt axiomatisch opgebouwd zoals de meetkunde van Euklides. Proefondervindelijke waarneming is de enige en volstrekt objectieve arbiter. Beperking van haar doel is een zeer vruchtbare strategie gebleken voor de natuurwetenschap. In der Beschränkung zeigt sich der Meister.
Religie is een moeilijk precies te definiëren begrip. Religie tracht onder andere een zin te geven aan het leven en doet typisch ook een beroep op geloof in hogere, niet precies bepaalde, essenties zoals God. Er bestaat geen overlap tussen de methodiek van de natuurwetenschap en religie. Daarom is er geen geldige basis voor dispuut tussen natuurwetenschap en religie. Zij kunnen in harmonie naast elkaar leven.
Creationisme, algemeen gedefinieerd, gaat uit van het geloof dat een ad hoc scheppingsdaad het heelal, de aarde, de dieren en de mens heeft gecreëerd. Wanneer zij dan stellen dat de wereld in zes dagen werd geschapen en dat het heelal zowat 6000 jaar oud zou zijn, doen ze uitspraken die behoren tot het domein van de natuurwetenschap. Wie dergelijke absurditeiten tot dogma wil verheffen kan zich, met de steun van Voltaire, beroepen op de vrije meningsuiting, die ook niet verbiedt te beweren dat de aarde plat is.
Natuurwetenschap en creationisme naast elkaar behandelen in het onderwijs is het mengen van onderling incompatibele en niet gelijkwaardige categorieën. Goede nabuurschap is hier onmogelijk.
Aan leerlingen onderwijzen dat er anno 2007 creationisten bestaan die nonsens verkondigen over de evolutielijkt geschikt, maar dan in cursussen over wereldbeschouwing of gedragswetenschappen... In deze lessen kan de leerkracht de methodiek of het uitgangspunt van verschillende wetenschapsdisciplines, van de religies en ook van bewegingen zoals creationisme, intelligent design, teleologie (die doelgerichtheid in het heelal poneert) en zelfs van de astrologie kritisch toelichten.
Kritische benadering is even belangrijk bij het natuurwetenschappelijk onderzoek, waarin ze trouwens inherent is ingebouwd. Ook de meest 'exacte' wetenschap gaat uit van hypothesen, die als axioma's fungeren waarop een theorie wordt geconstrueerd. Met behulp van het doorgedreven vergelijken van de voorspellingen van de theorie met steeds meer verfijnde experimenten, worden de hypothesen en de theorie voortdurend getoetst op hun geldigheidsdomein. Bij de biochemie en de evolutietheorie zijn de hypothesen, vanwege de aard van het onderzoek naar de oorsprong en de ontwikkeling van de levende materie, minder rigoureus uitgebouwd dan bij de fysica en de chemie. Maar de evolutietheorie is opgebouwd volgens de strikte regels van de natuurwetenschap. De evolutieleer behoort tot de grote scheppingen van de menselijke geest.
Het creationisme is zoals de draak Hydra: telkens als men een kop afhakt verschijnen er twee nieuwe. In 1925 was het onderricht over evolutietheorie nog wettelijk (het Scopes-proces) verboden in de staat Tennessee. Nadat de rechtspraak in de Verenigde Staten achtereenvolgens had beslist dat de evolutietheorie mocht worden onderwezen, dat creationisme niet mocht worden onderwezen, en ten slotte dat creationisme-wetenschap geen wetenschap is (Supreme Court 1987), kon worden gedacht dat de discussie was afgerond. Maar een tiental jaren geleden verscheen het creationisme in een gemuteerde vorm van intelligent design, inclusief financieel machtige lobby's en denktanks. De discussie kon herbeginnen en leidde, nu in Pennsylvania, tot een soort heruitgave van het Scopes-proces, het Dover-proces met als verdict dat intelligent design geen wetenschap is.
Het is opmerkelijk dat recent acties om creationisme of intelligent design op te nemen in het wetenschappelijk curriculum de kop opsteken in Europa, mee gedragen door sommige politici en gezagsdragers. Letizia Moratti, minister van Onderwijs in Italië, verwijderde in 2004 de evolutieleer als leervak in het middelbaar onderwijs. Er zijn zeer actieve 'pro creationisme' of 'pro intelligent design' pressiegroepen in Rusland, Frankrijk, het Verenigd Koninkrijk en Turkije. Het onderwijs over de evolutietheorie is een zeer politieke kwestie aan het worden. Dit is een verontrustende ontwikkeling en er bestaat in essentie geen rationele basis is voor een debat.
Vanzelfsprekend moet de evolutieleer prominent aan bod komen bij de eindtermen, net als wiskunde, natuurwetenschappen, geesteswetenschappen, sociale wetenschappen, kunst en cultuur, talen, geschiedenis,.... Er is evenzeer plaats voor lessen over levensbeschouwelijke vakken en gedragswetenschap. Dat er geen plaats is voor creationisme, intelligent design, astrologie... is even klaar en dat heeft niets te maken met een al dan niet vrijzinnige invalshoek.
Op wetenschappelijk vlak betekenen creationisme en intelligent design geen bedreiging. Hun verstrengeling met de politiek is wel verontrustend.
Jozef T. Devreese is hoogleraar emeritus in de theoretische natuurkunde aan de Universiteit Antwerpen en aan de Technische Universiteit Eindhoven.
Nature434, 724-731 (7 April 2005) | doi:10.1038/nature03466; Received 25 October 2004; Accepted 11 February 2005
Generation and annotation of the DNA sequences of human chromosomes 2 and 4
LaDeana W. Hillier1, Tina A. Graves1, Robert S. Fulton1, Lucinda A. Fulton1, Kymberlie H. Pepin1, Patrick Minx1, Caryn Wagner-McPherson1, Dan Layman1, Kristine Wylie1, Mandeep Sekhon1, Michael C. Becker1, Ginger A. Fewell1, Kimberly D. Delehaunty1, Tracie L. Miner1, William E. Nash1, Colin Kremitzki1, Lachlan Oddy1, Hui Du1, Hui Sun1, Holland Bradshaw-Cordum1, Johar Ali1, Jason Carter1, Matt Cordes1, Anthony Harris1, Amber Isak1, Andrew van Brunt1, Christine Nguyen1, Feiyu Du1, Laura Courtney1, Joelle Kalicki1, Philip Ozersky1, Scott Abbott1, Jon Armstrong1, Edward A. Belter1, Lauren Caruso1, Maria Cedroni1, Marc Cotton1, Teresa Davidson1, Anu Desai1, Glendoria Elliott1, Thomas Erb1, Catrina Fronick1, Tony Gaige1, William Haakenson1, Krista Haglund1, Andrea Holmes1, Richard Harkins1, Kyung Kim1, Scott S. Kruchowski1, Cynthia Madsen Strong1, Neenu Grewal1, Ernest Goyea1, Shunfang Hou1, Andrew Levy1, Scott Martinka1, Kelly Mead1, Michael D. McLellan1, Rick Meyer1, Jennifer Randall-Maher1, Chad Tomlinson1, Sara Dauphin-Kohlberg1, Amy Kozlowicz-Reilly1, Neha Shah1, Sharhonda Swearengen-Shahid1, Jacqueline Snider1, Joseph T. Strong1, Johanna Thompson1, Martin Yoakum1, Shawn Leonard1, Charlene Pearman1, Lee Trani1, Maxim Radionenko1, Jason E. Waligorski1, Chunyan Wang1, Susan M. Rock1, Aye-Mon Tin-Wollam1, Rachel Maupin1, Phil Latreille1, Michael C. Wendl1, Shiaw-Pyng Yang1, Craig Pohl1, John W. Wallis1, John Spieth1, Tamberlyn A. Bieri1, Nicolas Berkowicz1, Joanne O. Nelson1, John Osborne1, Li Ding1, Rekha Meyer1, Aniko Sabo1, Yoram Shotland1, Prashant Sinha1, Patricia E. Wohldmann1, Lisa L. Cook1, Matthew T. Hickenbotham1, James Eldred1, Donald Williams1, Thomas A. Jones2, Xinwei She3, Francesca D. Ciccarelli4, Elisa Izaurralde4, James Taylor5, Jeremy Schmutz6, Richard M. Myers6, David R. Cox6,10, Xiaoqiu Huang7, John D. McPherson1,10, Elaine R. Mardis1, Sandra W. Clifton1, Wesley C. Warren1, Asif T. Chinwalla1, Sean R. Eddy2, Marco A. Marra1,10, Ivan Ovcharenko8, Terrence S. Furey9, Webb Miller5, Evan E. Eichler3, Peer Bork4, Mikita Suyama4, David Torrents4, Robert H. Waterston1,10 and Richard K. Wilson1
Genome Sequencing Center, Washington University School of Medicine, Campus Box 8501, 4444 Forest Park Avenue, St. Louis, Missouri 63108, USA
Howard Hughes Medical Institute and Department of Genetics, Washington University School of Medicine, St. Louis, Missouri 63110, USA
Genome Sciences, University of Washington School of Medicine, Seattle, Washington 98195, USA
Center for Comparative Genomics and Bioinformatics, Departments of Biology and Computer Science, Pennsylvania State University, University Park, Pennsylvania 16802, USA
Stanford Human Genome Center, Department of Genetics, Stanford University School of Medicine, Stanford, California 94305, USA
Department of Computer Science, Iowa State University, Ames, Iowa 50011-1040, USA
EEBI Division and Genome Biology Division, Lawrence Livermore National Laboratory, Livermore, California 94550, USA
Center for Biomolecular Science and Engineering, University of California, Santa Cruz, California 95064, USA
Present addresses: Perlegen Sciences Inc., 2021 Stierlin Court, Mountain View, California 94943, USA (D.R.C); Baylor College of Medicine, 1 Baylor Plaza, Human Genome Sequencing Center, N1519, Houston, Texas 77030, USA (J.D.M.); Genome Sciences Centre, British Columbia Cancer Agency, 600 West 10th Avenue, Room 3427, Vancouver, British Columbia V5Z 4E6, Canada (M.A.M.); Department of Genome Sciences, Box 357730, University of Washington, 1705 NE Pacific Street, Seattle, Washington 98195-7730, USA (R.H.W.).
Correspondence to: Richard K. Wilson1 Correspondence and requests for materials should be addressed to R.K.W. (Email: rwilson@watson.wustl.edu). All reported DNA sequences have been deposited in GenBank or EMBL. Accession numbers for the chromosome sequence analysed for this paper can be found in Supplementary Table 1. The updated chromosome 2 and 4 sequences can be accessed through GenBank accession numbers NC_000002 (chromosome 2) and NC_000004 (chromosome 4). Primate resequencing data can be accessed using GenBank accession numbers CZ179368CZ179565. The mRNA resequencing data can be accessed via GenBank/dbSNP identifiers ss35032449ss35032461, ss35033273ss35033317.
Human chromosome 2 is unique to the human lineage in being the product of a head-to-head fusion of two intermediate-sized ancestral chromosomes. Chromosome 4 has received attention primarily related to the search for the Huntington's disease gene, but also for genes associated with Wolf-Hirschhorn syndrome, polycystic kidney disease and a form of muscular dystrophy. Here we present approximately 237 million base pairs of sequence for chromosome 2, and 186 million base pairs for chromosome 4, representing more than 99.6% of their euchromatic sequences. Our initial analyses have identified 1,346 protein-coding genes and 1,239 pseudogenes on chromosome 2, and 796 protein-coding genes and 778 pseudogenes on chromosome 4. Extensive analyses confirm the underlying construction of the sequence, and expand our understanding of the structure and evolution of mammalian chromosomes, including gene deserts, segmental duplications and highly variant regions.
Less than 50 years after the human diploid number was established, the reference human genome sequence was announced1. Detailed accounts of the sequences of individual chromosomes are now providing great insights into genomic structure and evolution. Here we present our analysis of the sequence of human chromosomes 2 and 4. For chromosome 2, we analyse the region containing the ancestral chromosome fusion event2 and describe possible mechanisms for the inactivation of the vestigial centromere. For chromosome 4, we discover some regions with the lowest and highest (G + C) content in the human genome, as well as the putative largest 'gene deserts'. Analyses of highly variant regions found on these chromosomes have also allowed us to investigate their origins.
13-09-2007 om 13:49
geschreven door Tsjok45
10-09-2007
knack lezer
Als je kijk naar de vragen van eos, dan blijkt daar ook een onvoldoende kennis van de wetenschap.
Naast het " apenvraagje " , wat hier al is behandeld
op 28-08-2007 "wetenschaps quiz "
iqsw er de verkeerde vraagstelling rond "het" gat in de ozonlaag ....., er zijn er immers 2 : een boven beide polen, het is wel zo dat deze boven de zuidpool het grootste is, maar dan moet je je vraag maar correct stellen.
Op die manier stel ik me dan ook wel de vraag of hun enquete relevant is(daarbij genomen dat jongeren zich meestal uitleven als ze een enquete krijgen op school...deden wij ook)
Dus 2 tips voor het eos team:
1) hun wetenschappelijke kennis toch eens op punt stellen tot het niveau van een middelbaar onderwijs. 2) bij het opstellen van een dergelijke vragenlijst eens terugdenken aan hoe men zelf(of dan toch de rest van z'n studiegenoten) was en hierop anticiperen door betere vraagstelling.
dannyvanpoucke(op maandag 27 augustus 2007)
10-09-2007 om 00:09
geschreven door Tsjok45
30-08-2007
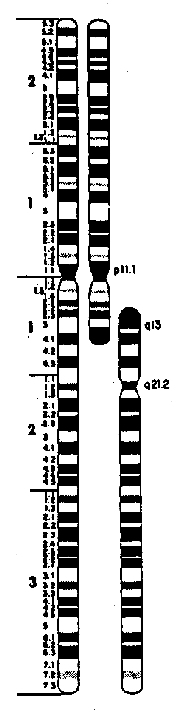
chromosoom #2
Chromosoom #2
Menselijk chromosoom #2 bewijst evolutie (video)
Geschreven door Danny de Kruijk
maandag 18 juni 2007
We weten allemaal dat veel mensen pro-schepping zijn. De meeste van ons weten ook dat het geloof hierin nergens op slaat.
Bewijzen voor evolutie zijn er overal, en vrij recent is er een ontdekking gedaan die bewijst dat de huidige mens-apen en de moderne mens ( homo sapiens ) dezelfde voorouder hebben). Die ontdekking is dus nu gedaan en de scheppingsgelovigen hebben hier nog niet op gereageerd,(1) ze kunnen het namelijk niet weerleggen.
Het filmpje waar het om gaat, gaat over de fusie van chromosonen. Het filmpje is een onweerlegbaar bewijs dat het zeer onwaarschijnlijk maakt dat wij geschapen zijn zoals de bijbel dat beweerd.
Korte uitleg:
P.S. (1) De enige creationist die het tot nu toe heeft geprobeert is Dr P. Borger
30-08-2007 om 17:37
geschreven door Tsjok45
28-08-2007
Wetenschaps-quiz
Doe zelf de test
De quiz bestaat uit dezelfde vragen die in het onderzoek van Eos gebruikt werden.
"Aap" Eigenlijk word het woordje " aap" in het nederlands gebruikt als synoniem van allerlei primaten uit de oude en de nieuwe wereld ... De engelse spreektaal-term is " monkey " ...
"Ape" (uit de spreektaal ) letterlijk vertalen door aap is dus verkeerd ... "ape" gaat nml over de mensapen van de superfamilie hominoidea( waaronder de gibbons ( familie Hylobatidae ) van de " monkeys" uit de oude wereld (infraorde catharini )
" Great apes " gaat over de afrikaanse mensapen en de oerang outang )(= onderdeel van de familie Hominidae ) allen met een karyotype van 48 chromosomen ( 2x 24) en uiteraard ook de mens met 46 chromosomen (2x23) ...
Nota : Twee van de mensapen- chromosomen zijn gefusioneerd in het menselijke haploide karyotype van de geslachtscel ( fusie chromosoom 2) http://www.genome.gov/13514624
Op het totaal van 28 vragen en stellingen haalt de Belg gemiddeld een resultaat van 58%. De vlaming doet het over de hele peiling 5% beter dan zijn landgenoot. Ook tussen de verschillende leeftijdscategorieën zien we duidelijke verschillen.
28-08-2007 om 15:51
geschreven door Tsjok45
23-08-2007
De eerste bedenkingen
Frank Van Den Broecke ; Publicatiedatum : 2007-08-23
" Je kunt je redeneervermogen ontdekken en ontwikkelen met theoretische kwesties en op die manier werken aan jezelf Maar je kunt ook je andere capaciteiten ontwikkelen bij meer vaardigheidsgerichte aspecten van het onderwijs: hoe los ik een probleem op, heb ik daar geduld voor of wind ik me op? Wat kan ik daaraan doen?
De minister geeft toe dat een groot deel van de bevolking niet mee is op dat onderdeel. Toch schaar ik me niet achter de stelling dat het vroeger beter was. Ik wil ook niet gezegd hebben dat jongeren minder werken, omdat ze net over veel meer zaken iets moeten weten. Het domein van de wetenschappelijke kennis is enorm uitgebreid en groeit nog steeds.
Vandenbroucke wil ook niet dat het cognitieve als enige maatstaf wordt genomen. Ik denk dat er voldoende kennis moet zijn, maar er is vooral ook nieuwsgierigheid nodig om kennis te blijven verzamelen en de vaardigheid om die kennis goed toe te passen. Daarom heeft het onderwijs een evenwicht nodig tussen overdracht van kennis, de vaardigheid om die kennis om te zetten in praktisch inzicht en een houding van nieuwsgierigheid en willen bijleren, aldus nog de minister in Eos.
Fientje Moerman ; Publicatiedatum : 2007-08-23
Vlaanderen moet de inspanningen voor de popularisering voor wetenschap, techniek en technologische innovatie voortzetten. Dat is volgens Vlaams minister van Wetenschap en Innovatie Fientje Moerman (Open VLD) de conclusie die valt te trekken na de enquête van het wetenschappelijke tijdschrift Eos waarin gepeild werd naar de wetenschappelijke kennis van Belgen.
Johan Braeckman doceert wijsbegeerte aan de universiteit van Gent. De Morgen / Publicatiedatum : 2007-08-23
De enquête van het tijdschrift Eos over de wetenschappelijke feitenkennis van de Belg doet stof opwaaien. Als een derde van de 18- tot 34-jarigen niet weet dat de aarde rond de zon draait, moeten we dan lachen of huilen?
Iedere generatie denkt dat het met de kennis van de jeugd van tegenwoordig slecht gesteld is. Het is niet erg moeilijk om daar met enkele goed gemikte vragen 'bewijzen' van te vinden. Zo stelt Eos vast dat jongeren, ook al zijn ze erg vertrouwd met de computer, weinig afweten van de technologie die er achter schuilgaat. Maar ook hier kun je je afvragen waarom dat problematisch is.
De derde wet van sciencefictionschrijver Arthur C. Clarke luidt dat geavanceerde technologie op een bepaald moment niet meer te onderscheiden is van magie. De meerderheid van dagelijke gebruiksvoorwerpen is voor het overgrote deel van de bevolking magisch, in die zin dat we eigenlijk niet begrijpen hoe al die dingen functioneren. Wie weet hoe een televisie werkt? De magnetron? Het navigatiesysteem in de auto? De benzinemotor? We kennen er het abc niet van, maar dat belet de meesten onder ons niet om ze dagelijks vrij succesvol te gebruiken. Een gebrek aan feitenkennis en weetjes is slechts problematisch voor wie in Blokken of de Canvascrack wil scoren.
Veel ernstiger is dat uit de enquête ook blijkt dat de meeste mensen geen degelijke methodes hebben om betrouwbare van minder betrouwbare informatie te onderscheiden.
De Amerikaanse fysicus Richard Feynman schreef ooit het volgende: "Je kunt de naam van een vogel kennen, in alle talen van de wereld, zonder iets van de vogel zelf te weten. Laat ons daarom de vogel bestuderen en kijken hoe hij leeft en wat hij doet. Dat is wat echt belangrijk is. Ik leerde al vroeg het onderscheid tussen de naam van iets kennen enerzijds en iets kennen anderzijds." Die laatste vorm van kennis ontstaat dankzij inzicht in de verschillen tussen betrouwbare en minder betrouwbare informatie. Weten hoe de wetenschappelijke methode werkt is daarvan een zeer belangrijk aspect, maar het is niet het enige. Men moet inzicht krijgen in het onderscheid tussen verschillende soorten bronnen: in de psychologische mechanismen die ons vaak tot foute conclusies brengen, in de relativiteit van het belang van anekdotes en ooggetuigen, in de wijze waarop drogredenen ontstaan en functioneren, enzovoort.
Kortom, mensen moeten leren wat kritisch denken betekent. Van belang is niet dat je weet hoe internet precies functioneert, maar wel dat je in staat bent om in die enorme hoeveelheid aan informatie het kaf van het koren te scheiden.
Van belang is niet dat je weet dat de telefoon in 1876 is uitgevonden, maar wel dat je beseft dat homeopathie een pseudowetenschap is.
In de discussie die onlangs in De Morgen en De Standaard werd gevoerd over de evolutietheorie, bleek er nagenoeg consensus te bestaan over het standpunt dat het creationisme niet thuishoort in de les biologie. Dat is volkomen terecht, maar dat wil niet zeggen dat we het creationisme daarom moeten doodzwijgen.
Integendeel, het creationisme en andere vormen van negationisme (holocaustontkenning, complottheorieën over 9/11), evenals pseudowetenschappen zoals homeopathie en astrologie, zijn net interessant om het verschil duidelijk te maken tussen kritisch en onkritisch denken, tussen het bevrijdende van de wetenschappelijke twijfel en het dogmatische van de pseudozekerheid.
Richard Feynman bestudeert een vogel die leeft en rondvliegt, pseudowetenschappen houden zich bezig met een dode mus.
Is ID de wetenschappelijke (sic) uitleg voor creationiisten 150jaar Darwinisme... De evolutietheorie gewikt en gewogen David sorensen en revolutietheorie lalala DE VERRIJZENIS VAN DE JONGE VERDRONKEN KOE » Reageer (21) ID TOVERDOOS OVER SLECHTE ID-EETJES ,RESISTENTIE & TOVERDOCTORS c) OEC d) YEC
Een oeroud spoor Denisova : ZUID SIBERIË DENISOVA - mens
DMANISI AAP OF MENS DE OUDSTE ? » Reageer (1)Nakalipithecus nakayamai (<) Alweer eentje ? ..... De tand des tijds / Heidelberg-mens DE HEUPEN VAN EVA CASABLANCA MAN /erectus Hobbit is aparte soort ? » Reageer (2) NOG EEN BENDE BIJTERS POLONAISE met neanderthaler TANDEN UIT DE QESEM GROT Neanderthaler genoom Mitochondriale Genenkaart van Neanderthaler Xuchang mens
b)Biologie 1.-(EVOLUTIE ) NAS / IM Document 2008 (2) NAS / IM Document 2008 ( 1)
Cambrium & precambrium AVALON GABONESE chips
Evolutie in actie Opmerkelijk snelle adaptaties bij kroatische ruine-hagedissen:
EEN PLUIM VOOR CHINA Geef eens een pootje Pluimgewicht KLEIN DUIMPJE & DE REUS &VEREN Opnieuw gevederde Maniraptor Similicaudipteryx. Aerosteon riocoloradensis
Krokodillen
PAKASUCHUS KAPILIMAI Prestosuchus chiniquensis Terug naar zee viseter
Eritherium azzouzorum LJOEBA Darwinius masillae VLIEGENDE KATTEN ? Vleermuizen ALWEER EEN BELANGRIJK STUK UIT DE LEGPUZZEL Zee-zoogdieren ; Van de wal in de visgronden Indohyus / walvisevolutie Zeehonden-evolutie
*Blauwe en groene ( =nederlandse)teksten zijn meestal aanklikbare links *Engelse Wikipedia teksten verwijzen in de linkerkolom naar verschillende niet-engelse versies van het wikiartikel *Blauwe teksten tusssen "" , zijn voornamelijk ( gedeeltelijke)citaten afkomstig van mensen met andere meningen
Evolutie / Charles Darwin aan de basis: SELECTIE NATUURLIJK DE LEVENSBOOM UITSTERVEN DEEP TIME Biogeografie SEKSUELE SELECTIE Al jaren lang samen CO-EVOLUTIE De economie van de natuur Geleidelijke veranderingen
Unintelligent design:
IP Theorie Ons gebit , De appendix, Geboorte, De weg van het zaad , Nervus Laryngeus Recurrens, DNA , 75 mistakes , Het boek
Unintelligent design (1): Rechtop lopen Tomaso over het oog , oogspieren , Unintelligent Design (5): ZWEETVOETEN Unintelligent design (6): Vitamine C Unintelligent design (8): Kuitspieren
 Unintelligent design (1): Rechtop lopen
Unintelligent design (1): Rechtop lopen








 Tomaso schrijft over
Tomaso schrijft over 





{kind=link}