Every programmer has to debug programs, but debugging programs that aren't run in an interactive job can be tricky. Batch jobs, trigger programs, never-ending programs, server programs, exit programs, CGI programs . . . all these types of jobs are run in the background by some sort of automatic process. Finding the background job and running the debugger on it can be a challenge.
Traditionally, programmers have debugged batch jobs by holding the job queue, running the Start Service Job (STRSRVJOB) command to specify the job to debug, and then running the Start Debug (STRDBG) command. Finally, they release the job queue. What a pain! And when you're not issuing the SBMJOB command yourself, how do you even know which job queue to hold?
In V5R2, the folks at IBM provided an easier way called Service Entry Points (SEP). This article discusses how you can use SEP to debug your programs, both in WDSc and in the green-screen debugger.
Using SEP from the Green Screen
With the standard STRDBG tool, you can use SEP from a green-screen terminal. Unfortunately it's rather awkward. But it works, and sometimes, especially when you're out in the trenches, you have no access to the more advanced debugger in WDSc.
Here's how you set a SEP breakpoint:
Start debugging the program in your current job by typing the following command:
STRDBG PGM(my-library/my-program)
Review the source code on the screen. In the leftmost column of the screen, you see the line numbers that the debugger uses to refer to each line of code in your program. Find the line number of the statement in which you want to place the SEP breakpoint.
At the command line in the debugger, use the sbreak command, followed by the line number at which the program should stop. If you want a different user aside from the current one, you should also specify the user when you run the sbreak command. For example, if the line number is 145 and the user is QUSER, you type the following:
sbreak 145 user QUSER
When the break point has been set, press F12 to let the debugger run.
As soon as the specified user runs your program and reaches the breakpoint on any job anywhere in the system, the user's program stops, and a notification message is sent to the terminal on which STRDBG was run.
If you press the F1 key to get extra information about the message, you get a display like the following:
Additional Message Information
Message ID . . . . . . : CPI1903
Date sent . . . . . . : 01/09/07 Time sent . . . . . . : 23:40:07
Message . . . . : Service Entry Point has stopped at line 2 in program
LIBSCK/TESTCALL in job 584077/KLEMSCOT/QPADEV000R.
Cause . . . . . : Service Entry Point has stopped at line 2 in program
LIBSCK/TESTCALL in job 584077/KLEMSCOT/QPADEV000R.
Recovery . . . : This program must be debugged from a servicing job. Do a
Start Service Job (STRSRVJOB JOB(584077/KLEMSCOT/QPADEV000R)). Then do Start
Debug (STRDBG) on the spawned job from where the STRSRVJOB was done. Set a
local breakpoint at or after the Service Entry Point. Return to the original
job and press enter to release the spawned job.
Bottom
Press Enter to continue.
F1=Help F3=Exit F6=Print F9=Display message details
F10=Display messages in job log F12=Cancel F21=Select assistance level
Here's the part that makes the green-screen tool awkward: To use this information, you have to run STRSRVJOB and STRDBG on the job number and program reported in the preceding notification message. But you can't run it in the same job! You can't issue STRSRVJOB in the same job, because that job is already in debug. You can't end the debug session in that job, or you'll release the SEP breakpoint.
You have to go to a separate 5250 window and key the following commands:
The first line can be copied and pasted from the notification message. Make sure that you use the same job information that appeared in the notification message! The second command, the STRDBG command, is needed to start debugging on the new job.
Set a new breakpoint (it can be in the same place) so that the program stops in the servicing job, and debug it as you typically would. After this breakpoint has been set, the SEP breakpoint gets removed, so you can feel free to end the debugger on the first 5250 screen.
Because my programs never have any bugs, I've never needed to debug them. << SMACK! >> Oh, sorry, I was dreaming there for a moment. It was such a nice dream, too.
Every programmer has to debug programs, but debugging programs that aren't run in an interactive job can be tricky. Batch jobs, trigger programs, never-ending programs, server programs, exit programs, CGI programs . . . all these types of jobs are run in the background by some sort of automatic process. Finding the background job and running the debugger on it can be a challenge.
Traditionally, programmers have debugged batch jobs by holding the job queue, running the Start Service Job (STRSRVJOB) command to specify the job to debug, and then running the Start Debug (STRDBG) command. Finally, they release the job queue. What a pain! And when you're not issuing the SBMJOB command yourself, how do you even know which job queue to hold?
In V5R2, the folks at IBM provided an easier way called Service Entry Points (SEP). This article discusses how you can use SEP to debug your programs, both in WDSc and in the green-screen debugger.
Over the last five years, I've written quite a bit of material about processing IFS files from an RPG program. Most of the material that I've written demonstrates using the open() and read() APIs to read text from an IFS file.
This technique works great for many IFS files, but it can be awkward when you're processing a text file. A text file is a file in which the records aren't always the same length. Instead of reading fixed-length records, each record ends when the carriage return and line feed (CRLF) characters are found. Unfortunately, this doesn't work so well with the open() and read() APIs, because reading a file one character at a time is not very efficient! This article demonstrates a different API that makes reading text file records easy without sacrificing efficiency.
The reason the read() API can't do this type of reading efficiently is because it goes back to the disk each time you attempt to read a byte. This frequency is no problem when you read large amounts at once, because data is transferred from disk to memory only once. However, when you read a file one byte at a time, each call to the read() API requires it to transfer data from disk to memory. The extra overhead of doing that repeatedly for only one byte at a time causes poor performance.
Fortunately, an alternative exists. ILE C has a set of APIs different from the familiar open(), read(), and close() ones. Because ILE languages can call subprocedures written in other ILE languages, you can use these ILE C APIs from your RPG program.
These alternative APIs are useful because they load data from disk more efficiently. They calculate the optimal size of data to be read at once from the file, and then they load that much from disk at a time. The data, once loaded, is kept in memory in a buffer. Each time you try to read the file, it first reads from the buffer and only goes back to disk once the buffer is used up.
This disk buffering technique is similar in concept to the "record blocking" that we're used to using in RPG, except that it works on stream files rather than traditional record-based files.
The ILE C stream file access APIs are as follows:
fopen(): Open a file.
fclose(): Close a file.
fread(): Read bytes from a file.
fwrite(): Write bytes to a file.
fgets(): Get a line of text from a CRLF-delimited text file.
fputs(): Write a line of text to a CRLF-delimited text file.
fseek(): Seek (i.e., move the file cursor) to a particular position in the file.
ftell(): Return the current position in the file.
I've written a copy book that contains all the prototypes and constants needed to use these APIs from ILE RPG. I named this copybook STDIO_H, and it's included in the code download for this article.
The most interesting of these APIs is the fgets() API. It takes care of all the work of reading the data from the stream file until a CRLF delimiter is found. You no longer have to code a loop that reads the file byte-by-byte looking for the CRLF characters! Woo hoo!
Before you can call fgets(), you have to open the file by calling the fopen() API. Here's code that does that:
D file s like(pFILE)
.
.
filename = '/home/scott/testfile.txt';
file = fopen(%trimr(filename): 'r');
if (file = *NULL);
// error occurred! Check errno!
endif;
The first parameter to the fopen() API is the IFS path name to the file that you want to open. You should always use the %trimr() (or a comparable method) to remove any trailing spaces from the file name.
The second parameter tells the system how you want to open the file. It can have the following values:
r Open the file for reading only.
r+ Open the file for reading and writing.
w Create the file if it does not exist, or clear the file if it does exist. Then open it for writing only.
w+ Same as "w," except that the file is opened for reading and writing.
a Open the file for writing only and create it if it doesn't exist. All data is always written at the end of the file. You cannot overwrite existing data in the file.
a+ Same as "a," except that the file is opened for reading and writing.
The preceding options are alternatives to one another. You can specify only one of them.
Some optional modifiers can also be added to enable special processing of the IFS file. These modifiers are added to the end of the option that you choose. The modifiers are:
b This can be added to any of the preceding values to open the file in "binary" mode. In binary mode, data is not translated from one character set to another (e.g., ASCII to EBCDIC translations do not occur).
o_ccsid=xxxxx This keyword has to be separated from the preceding ones by a comma. It specifies the Coded Character Set Identifier (CCSID) of the data that you intend to write to the file. If the file doesn't exist, it gets tagged with this CCSID. If the file does exist, it assumes that this CCSID is the CCSID of the data that you're providing to the fwrite() or fputs() APIs, and it converts from that CCSID to the one that the file was originally tagged with.
crln=N This specifies whether each line of text in the file ends with CRLF or only with LF. When you set this parameter to Y (the default) it looks for CRLF. If this is set to N, it uses LF only.
For example, the following statement creates a new file and assigns it CCSID 819:
D file s like(pFILE)
.
.
filename = '/home/scott/newfile.txt';
file = fopen(%trimr(filename): 'w,o_ccsid=819');
if (file = *NULL);
// error occurred! Check errno!
endif;
The fopen() API returns a pointer that the API uses internally to keep track of which file it has open, its position in the file, and the status of the buffering. You don't have to worry about what this pointer is set to. All you need to do is keep it in a variable so you can pass that variable to the other APIs so that they know which file to read or write from.
If the fopen() API returns *NULL, an error has occurred, and you should check the errno value to see what went wrong. This is the same errno used with the IFS APIs and socket APIs. If you're unfamiliar with this concept, please see the following article: http://www.systeminetwork.com/article.cfm?id=19312
After the file is opened, you can call the fgets() API to read data as lines in a text file. The fgets() API takes care of all the buffering and searching for CRLF for you.
D p_line s *
D rddata s 8000a
D line s 8000a varying
.
.
p_line = fgets(%addr(rddata): %size(rddata): file);
dow (p_line <> *null);
line = %str(p_line);
// now the "line" variable contains one line
// of text from the IFS file! Insert code here
// to use that line for whatever you need to
// use it for...
p_line = fgets(%addr(rddata): %size(rddata): file);
enddo;
The fgets() API accepts three parameters: a pointer to a buffer, the size of the buffer, and the file pointer to read from. The first pointer should be the address of a variable in your program. This is where the fgets() API reads data into. The second parameter is the length (in bytes) of the variable that you specified in the first parameter. The last parameter is the value that you received when you called the fopen() API, and it tells the fgets() API which file to read from.
The fgets() API returns a pointer to the data that it has read if it's successful in other words, it returns a pointer to the variable that you specified in the first parameter! If you reach the end of the file, a *NULL pointer is returned, instead.
The data that the fgets() API loads into the variable (rddata in the preceding example) is a null-terminated string, like the ones usually used in C programs. To convert it to an RPG-style alphanumeric string, you call the %str() built-in function (BIF). In my example, I use the %str() BIF to convert the C-style string in the rddata variable to an RPG-style string in the line variable. After that's done, the line variable contains one line of text from the stream file and is ready for you to use in your program.
The preceding sample code calls fgets() again in a loop and continues to read the file until fgets() returns *NULL, indicating that the end of the file was reached.
After you're done with the file, you have to close it by calling the fclose() API. The only parameter that you have to pass is the file pointer that you received when you called the fopen() API. For example:
fclose(file);
To demonstrate the entire process, I've written an RPG program that reads a pipe-delimited text file. It reads the whole file, one line at a time, using the fgets() API. For each record, it uses a subprocedure that I wrote, called gettok(), to break each record up into fields. With minor modifications, this program could search for commas or tabs instead of pipes.
A: A CGI program is not limited to returning HTML. It can return any type of data. When you return data, you use the content-type HTTP header to designate the data type of the returned data. Apache is smart enough not to perform EBCDIC to ASCII translation when you return data that's not text.
In this article, I demonstrate how a CGI program can use the IFS APIs to read a file from the IFS and return it to a browser.
The IFS APIs can be used to read and write the standard input and output used with CGI programs. Although most articles and books tell you to use the QtmhRdStin() API to read standard input and the QtmhRdStout() API to write to standard output, these APIs are not the only methods of accomplishing these tasks.
You can also use file descriptors for the standard I/O streams. To do that, you should set the QIBM_USE_DESCRIPTOR_STDIO environment variable to Y. Though this setting appears unnecessary in Apache, it's required in other areas of the system, so for consistency, I feel that setting it is a good idea. When this variable is set, you can use the IFS read() and write() APIs to access standard input and output, respectively. To do so, use descriptor 0 for standard input and descriptor 1 for standard output. These descriptors do not need to be opened; Apache opens them before it calls your CGI program.
This method is ideal when you have a stream file in the IFS and you want to send it to a browser, because you can simply do the following:
D STDIN c 0
D STDOUT c 1
.
.
filename = '/home/klemscot/ifs_ebook.pdf';
pdf = open( %trimr(filename): O_RDONLY );
if (pdf = -1);
// handle error
endif;
//
// Specify the type of file and its filename.
// Note: change "inline" to "attachment" to let
// the user save it to disk.
//
text = 'Content-Type: Application/pdf' + CRLF
+ 'Content-Disposition: inline; filename='
+ %trimr(filename) + CRLF
+ CRLF;
callp write(STDOUT: %addr(text)+2: %len(text));
//
// Read the contents of the PDF file in binary
// mode and write it to stdout
//
len = read(pdf: %addr(buf): %size(buf));
dow len > 0;
callp write(STDOUT: %addr(buf): len);
len = read(pdf: %addr(buf): %size(buf));
enddo;
callp close(pdf);
To have Apache set the QIBM_USE_DESCRIPTOR_STDIO environment variable, you can insert the following into the Apache configuration under the library where your CGI program resides:
<Directory /QSYS.LIB/MYCGILIB.LIB>
Order Allow,Deny
Allow From all
SetEnv QIBM_USE_DESCRIPTOR_STDIO Y
</Directory>
If you change the content-type, you should be able to use the same technique to return other document types, such as Word or Excel documents, as well. You can return anything you like, as long as you pass back the correct content type.
Q: Is it possible to execute SQL statements from within a CL program?
A: Yes, you can run SQL statements from a CL program. To do so, you place your SQL statements in a source file member and then use command RunSQLStm (Run SQL Statements) to execute the statements in the member.
For example, suppose you wish to set field ProcFlag to value Y in all records found in file YourLib/YourFile. The following SQL statement accomplishes this:
Update YourLib/YourFile
Set ProcFlag = 'Y'
Simply create a source member with the above SQL statement and then in your CL program issue the following command:
You can run SQL statements in a batch job by submitting the RunSqlStm (Run SQL Statements) command. This command executes SQL statements stored in a source member. The source member can contain any valid SQL statements. Each SQL statement in the member must be separated by a semicolon.
Here's a simple example. Source member MySQL in file MySrc updates all the records in file InvMst and deletes selected records from file InvBal:
Update InvMst
set ImCls = 'AA',
ImTyp = '1';
Delete from InvBal
where IbQtyStk = 0;
To execute these SQL statements in batch with no commitment control, you would specify the following RunSqlStm command in the Cmd parameter of the SbmJob (Submit Job) command:
Sum character fields with decimals in SQL on the iSeries
SELECT sum(case when trim(mcm_ucop) = '' then 0 else cast(trim(mcm_ucop) as dec(11, 3)) end) as ucop, sum(case when trim(mcm_tadp) = '' then 0 else cast(trim(mcm_tadp) as dec(11, 3)) end) as tadp FROM mcm_
Field mcm_ucop and mcm_tadp are 15 characters : example 0000005187.570
I frequently have to create strings that consist of some known data and some variables. This requirement often leads me to write a rather complicated expression, such as the following one:
This type of expression can be a hassle to code. Mistakes (e.g., missing an apostrophe) are easy to make, and it's often unclear what the created string will be. To make this coding easier for myself, I wrote a utility named Parse. Using this utility, I can code the following:
The parse() procedure accepts one required parameter (the base string, containing substitution variables) and up to nine additional optional parameters (the substitution values themselves). The base string can contain up to nine separate substitution variables, in the form &n, where n is a number from 1 to 9, which refers to a substitution value parameter. A substitution variable can occur multiple times in the base string.
In the preceding example, the &1 variable is replaced with the first optional parameter, which is %trim(Lib). The &2 substitution variable is replaced with %trim(File), and so forth.
All the parameters are defined as pointers, with the OPTIONS(*STRING) keyword, which means that you can pass either a hard-coded string or a variable to the parse() procedure. Note that if a variable is passed, trailing blanks are included unless it's defined with the VARYING keyword or is passed with the %trim() or %trimr() built-in function (BIF).
Some examples of using parse() might be as follows:
D Base C 'My &1 is &2.'
D Type S 10A Inz('life')
.
.
/free
// Example 1: Simple string replacement (1)
String = parse( Base : 'name' : 'Rory Hewitt' );
// Result 1: String = 'My name is Rory Hewitt.'
// Example 2: Simple string replacement (2)
String = parse( '&1&3&2 &1&4&2' : '(' : ')' : 'value1' 'value2' );
// Result 2: String = '(value1) (value2)'
// Example 3: Passing an untrimmed variable
String = parse( Base : Type : 'good' );
// Result 3: String = 'My life is good.'
// Example 4: Passing a trimmed variable
String = parse( Base : %trim( Type ) : 'good' );
// Result 4: String = 'My life is good.'
/end-free
If a substitution value parameter that lacks a corresponding substitution variable in the base string is passed, it is simply ignored. In the following example, the last parameter is def, but it's ignored because the Base string has no &3:
D Base C 'My &1 is &2.'
.
.
String = parse( Base : 'job' : 'worker bee' : 'def' );
// Result: String = 'My job is 'worker bee'.'
If a substitution variable is found in the base string but has no corresponding substitution value parameter, it remains in the base string. In the following example, the result will contain &2 because I did not pass enough parameters to supply a replacement for the &2 variable:
D Base C 'My &1 is &2.'
.
.
String = parse( Base : 'life' );
// Result: String = 'My life is &2.'
Substitution variables (e.g., &3) passed in substitution value parameters are not themselves parsed. So in the following code, &3 is simply treated like any other substitution value:
D Base C 'My &1 is &2.'
.
.
String = parse( Base : '&3' );
// Result: String = 'My &3 is &2.'
However, you could use that string as input to a subsequent call to parse() where it would be used. In this next example, the first call to parse() simply replaces the substitution variable &1 with the substitution value &3; when parse() is called a second time, &3 is now a substitution variable in the base string, so it's replaced:
D Base C 'My &1 is &2.'
.
.
String = parse( Base : '&3' );
// Result: String = 'My &3 is &2.'
String = parse( String : 'ignored' : 'Rory Hewitt' : 'name' );
// Result: String = 'My name is Rory Hewitt.'
Using the parse() procedure makes seeing what the eventual command string will be easier. My original CRTPF example code is much simpler to understand when using parse() than when using lots of string concatenation, because the base string looks very similar to the eventual command. In fact, in addition to the base string being hard-coded or defined as a constant in the D-specs or in a compile-time array, it could be retrieved from a file at runtime, thus allowing you more flexibility when creating command strings for different environments or outputting form letters or whatever.
Creating Parse()
Because parse() is simply a procedure, I included no information about how to compile it. I suggest that you either put it into an existing module (perhaps one that already contains similar string-handling procedures) or create a new one, which you would then bind into a service program containing other "generic" procedures, such as string-handling and numeric conversion. Any program that needs to call parse() must /COPY in the PARSE_P copybook.
You can download the parse() utility from the following link:
You won't often find me extolling the virtues of an error message. After all, I pride myself on writing proper code. I don't want to receive errors. However, there's one error message that I think is one of the best enhancements ever made to the RPG language: RNQ0103 "Target for a numeric operation is too small to hold result."
Until recently, I thought that you could get this message only if you did your math in an expression, such as those used on an EVAL opcode. I thought that the old-style math opcodes (e.g., ADD, SUB, DIV, MULT) could not produce this error. Today, I discovered that they can.
The trick is the Truncate Numeric (TRUNCNBR) compiler option. You can specify TRUNCNBR(*NO) on the CRTRPGMOD, CRTBNDRPG, or H-spec to tell the compiler that you want the program to fail with an error if a value is too large to fit in the receiver variable. For example:
CRTBNDRPG PGM(myProgram) TRUNCNBR(*NO)
Why do I like this option so much? I like it because it prevents errors. Consider a report that lists all the payments that your accounting department needs to collect from customers. It totals all the invoices issued to each customer and subtracts all the previous payments to get the current balance. What happens if the total of invoices is too large for the receiver variable? You might not know that the customer owes anything! The customer might get away with short paying by thousands of euros!
When you specify TRUNCNBR(*NO), the program can send an error message. If you've written a *PSSR to trap errors, that *PSSR can notify someone that a problem exists, so that they can take corrective action. If you don't use a *PSSR or some other technique that monitors for errors, the program crashes and the user calls you for help.
SystemiPortal.com, which provides a System ispecific resource directory and in-depth search tools for news, technical information, forums, blogs, wikis, and more. The site is part of the new iSociety communitybuilding initiative.
Perhaps the biggest benefit to be derived from free form is one of legibility. In free form you may use the positioning of the code to help clarify the structure.
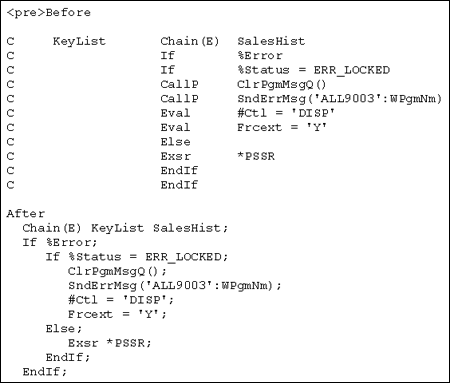
Figure 1 shows a comparison between a snippet of code written using extended Factor 2 and the exact same code in free form. The use of free form makes it easy to see the structure of the nested IFs and the IF/ELSE. Actually, the code shown in Figure 1 was converted to free form using an option in the Remote System Explorer (RSE) LPEX editor in Websphere Development Studio Client (WDSC) Source/Convert All to Free Form.
Increased legibility is also provided by the fact that you have more space on a line for code. This is especially useful when you start using qualified data structures, which lends to longer names on a line since field names must be qualified with the data structure name.
Of course, it is possible to write hard to read (if not illegible) code in free form but that can be said of whatever coding structure you use. I can write code as badly in free form as I do in fixed form but, on the other hand, I can write code that is a lot easier to read in free form than it is in fixed form.
Unsupported operation codes
Not all operation codes are supported in free form. Some operation codes have been replaced by Built-in Functions (BIFs) (e.g. %SUBST, %OCCUR, %XLATE) but other operation codes do not have a direct equivalent. The more obvious of these are the standard ADD, SUB, DIV, MULT, MOVE and MOVEL operation codes. Just as with extended Factor 2, these operation codes may be emulated with the EVAL operation but you must remember that EVAL is not as forgiving as the fixed format operation codes.
Numeric overflow is not tolerated by EVAL so you will receive a run-time error if you fill a numeric field as opposed to the value wrapping around to zero.
There is no direct equivalent of the MOVE operations; you must use BIFs (%CHAR, %DEC, %DATE, *INT) is you need to move data between fields with different data types and you may need to use %SUBST if you need to move data between fields of different lengths. A lot of people see this as a problem but I actually see it as an advantage in that it leads to self-documenting code. Compare the two lines of code shown in Figure 2. In the fixed format line you must be familiar with the definition of the two fields to understand what the MOVEL operation is achieving whereas the free form equivalent is self explanatory; it may not be as easy to code but it is easier to understand when you read it.
Figure 1 shows a comparison between a snippet of code written using extended Factor 2 and the exact same code in free form. The use of free form makes it easy to see the structure of the nested IFs and the IF/ELSE. Actually, the code shown in Figure 1 was converted to free form using an option in the Remote System Explorer (RSE) LPEX editor in Websphere Development Studio Client (WDSC) Source/Convert All to Free Form.
It is now possible to have a program that consists of fixed format, extended Factor 2 and free form RPG -- not a pretty site and something to be avoided if possible.
Extended Factor 2 operations will convert directly to free form but you need a third-party tool (or write one yourself) if you want to convert the unsupported operation codes to free form.
Only FREE
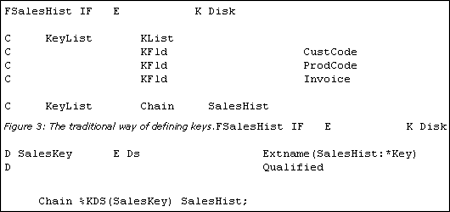
shows the traditional code for defining a key list to be used with a file where the key consists of a number of fields.
shows how a key list may be emulated in the D specs. An externally defined data structure is defined using the optional parameter of *KEY on the EXTNAME key word to indicate that only key fields from the external file are to be included in the data structure. This data structure is then used as an argument for the %KDS BIF on the CHAIN operation. The %KDS BIF may only be used in free form. This is slightly better than a key list in that the %KDS keyword makes it clear that a data structure is being used to define the key.
But Figure 7 shows the preferred way to access a record using multiple key fields. Simply provide the list of key fields to be used directly on the operation code. You may even use a literal and/or an expression as one of the key fields!
Another new language feature that is geared towards free form is the XML-INTO operation code (introduced in V5R4). You must use free form if you want to use either the E or H extender with XML-INTO since the length of the operation code and the extender is eleven characters as opposed to the ten allowed for the operation code in fixed form and extended Factor 2.
Netwerkkabels zijn kant-en-klaar te koop, maar vaak slechts beschikbaar in enkele maten en bovendien erg duur. Goedkoper is het om zelf kabels te maken. We laten u zien hoe u te werk moet gaan.
Voor het maken van kabels dient u 'UTP Ethernetkabel' in huis te halen. UTP staat voor Unshielded Twisted Pair en wordt gebruikt voor een netwerk op basis van een ster-topologie: vanuit één plaats, zeg maar de centrale netwerkswitch, vertrekken meerdere UTP-kabels naar de verschillende vertrekken in uw huis.
Er bestaan verschillende categorieën UTP-kabels, waarbij vooral de kwaliteit en de ondersteunde snelheden een rol spelen. Zo is UTP van categorie 5 prima geschikt voor netwerksnelheden tot 100 Mbit/s. Wilt u sneller gaan, dan investeert u bij voorkeur in UTP-kabels van categorie 6. Daarmee zijn snelheden tot 1.000 Mbit/s mogelijk.
Let er op dat de totale afstand tussen twee netwerkapparaten in een Ethernet-netwerk nooit meer dan honderd meter mag bedragen. Houd de afstand dus zo kort mogelijk, vooral omdat langere kabels een negatieve invloed hebben op de snelheid. Kabels van minder dan een halve meter zijn echter evenmin aan te raden.
Stap 1: Materiaal verzamelen Voor we aan de slag kunnen gaan, hebben we enkele zaken nodig. Ten eerste: een speciale krimptang. Een dergelijke tang wordt gebruikt om de netwerkstekkers op de netwerkkabel te drukken. Koop een krimptang die overweg kan met RJ45-stekkers. Er bestaan namelijk ook tangen die speciaal bedoeld zijn voor telefoonkabels (type RJ11). Natuurlijk hebben we ook nog RJ45-stekkertjes nodig: twee per kabel.
Voor de aanschaf van netwerkkabel moet u vooral uitkijken naar aanbiedingen voor bulkhoeveelheden - die zijn nu eenmaal goedkoper. Meestal komen deze in de vorm van een grote kartonnen doos met enkele honderden meters netwerkkabel. De doorsnee computerwinkel zal zoiets echter niet in voorraad hebben. Een kijkje op de veilingen van eBay of Marktplaats kan hier van pas komen (zoek op de term 'UTP'): zo vonden wij op eBay driehonderd meter UTP-kabel (categorie 5) voor zestig euro.
Stap 2: knippen en strippen Knip met behulp van een scherp mesje of een schaar de netwerkkabel op de gewenste lengte. Verwijder vervolgens drie centimeter van de buitenste plasticlaag van de kabel. U kunt daarvoor een speciale striptang gebruiken, maar met een stanleymesje kan het ook. Als de kabel eenmaal gestript is, ziet u binnenin vier gekleurde draadparen. Trek de draadparen los, zodat er acht aparte en vrij te bewegen aders vrijkomen.
Stap 3: kleurvolgorde Voor een goed werkende netwerkkabel moeten de gekleurde aders in de juiste volgorde naast elkaar gezet worden. Er bestaan hiervoor twee kleurenstandaarden, EIA/TIA 568B en 568A. Voor datacommunicatie maakt het in principe niet uit welke u gebruikt, zolang u maar consequent dezelfde standaard hanteert.
Wij kiezen voor de 568A-standaard, en dat betekent van links naar rechts de kleuren groen/wit, groen, oranje/wit, blauw, blauw/wit, oranje, bruin/wit en bruin (klik op de afbeelding bij dit artikel voor een schema). Zorg ervoor dat de aders perfect naast elkaar liggen, zonder kronkels; duw er eventueel met uw duim op om alles mooi glad te krijgen. Is dit gelukt, knip dan de bovenkant van de aders recht af met een schaar, zodat u zo'n twee centimeter van de blootliggende aders overhoudt.
Stap 4: inschuiven en krimpen Nu schuiven we de gekleurde aders in de RJ45-stekker. Let op de oriëntatie van de stekker: zorg dat het lipje naar beneden is gericht. Schuif er nu heel voorzichtig de acht aders in en duw deze aan tot aan de kop van de RJ45-stekker.
Neem nu de krimptang. Plaats de RJ45-stekker in de krimptang en druk deze aan. Voorzie vervolgens het andere uiteinde van de kabel op exact dezelfde manier van een RJ45-stekker, en uw netwerkkabel is klaar voor gebruik.
APIs by Example: Retrieve Job Description Information API
Job descriptions play a very important role in work management on the i5. Whenever an interactive, batch, autostart, or prestart job begins its life, a number of significant job attributes are retrieved from the job description assigned to that job. As a consequence, job descriptions need to be carefully created, managed, and assigned, or unexpected and serious problems might be the outcome.
As programmers, we can help avoid these problems by writing utilities that make the system administrator's job easier. To write utilities that work with job descriptions, understanding the Retrieve Job Description Information (QWDRJOBD) API is helpful.
For example, if a library contained in the initial library list of a job description is deleted, and that job description is assigned to a user profile, the user profile in question can no longer sign on to the system but instead receives the error message "CPF1113 Library in initial library list not found." To help avoid such situations, and provide a working example of the QWDRJOBD API, I've written the Work with Referenced Job Descriptions (WRKREFJOBD) command.
The WRKREFJOBD lets you find and list all job descriptions referenced by specific objects on your system, before deleting or renaming these objects. From the resulting list panel, you then have various options to perform against the selected job descriptions, such as change, display, or delete the job description.
The WRKREFJOBD utility also provides yet another opportunity to demonstrate how powerful it is to combine list and retrieve APIs. In this example, I use the Open List of Objects (QGYOLOBJ) API to create a list of job descriptions and subsequently, for each returned qualified job description name, I use the QWDRJOBD API to retrieve the attributes of the job description. Using this information, I then evaluate the specified selection criteria and decide whether the job description should be included in the Work with list panel.
You can specify all combinations of job description and library special values to narrow your search to specific or generic job descriptions in various libraries. To list all job descriptions in library QSYS that have a user profile specified, run the following command:
WRKREFJOBD JOBD(QSYS/*ALL) USRPRF(*ANY)
You also have an option to define the relationship between multiple selection criteria. If you specify an OR relationship, all job descriptions meeting just one of the criteria are included in the list. Specifying an AND relationship includes only the job descriptions meeting all the specified criteria.
The preceding command leads to the display of the following list panel (optionally, you can have the list printed instead):
The list panel offers three alternate views, all in all displaying each job description's user, print device, initial library list flag, partial request data, job and output queue as well as text description. Cursor-sensitive help text is provided for the list panel and the command to explain all details.
In case you are wondering how job descriptions are assigned to the different job types that I've mentioned, here's a brief overview:
Interactive jobs pick up the job description from the work station entry that they are signing on through. By the default special value *USRPRF, the work station entry points to the signing-on user profile's job description, as you can see on the partial command prompt of the Add Workstation Entry (ADDWSE) command:
Add Work Station Entry (ADDWSE)
Type choices, press Enter.
Subsystem description . . Name
Library . . . . . . . . *LIBL Name, *LIBL, *CURLIB
Work station name . . . . Name, generic*
Work station type . . . . *ALL, 3179, 3180, 3196...
Job description . . . . . *USRPRF Name, *USRPRF, *SBSD
Library . . . . . . . . Name, *LIBL, *CURLIB
To inspect how your system is set up, run the Display Subsystem Description (DSPSBSD) command against your interactive subsystem and select option 4 (Work station name entries) and 5 (Work station type entries). From each resulting panel, you can specify option 5 for the entry that you want to display.
Batch jobs rely on the Submit Job (SBMJOB) command's job description (JOBD) parameter to locate the job description under which the job should run. By default, this parameter also points to the special value *USRPRF. In this context, *USRPRF refers to the user profile specified on the SBMJOB command's user (USER) parameter, which by the default value *CURRENT points to the user profile running the SBMJOB command. So if the default values are used for these two parameters, the submitting user profile is the origin of the job description for the submitted batch job.
For prestart jobs and autostart jobs, the job description is named directly on the Add Prestart Job Entry (ADDPJE) and Add Autostart Job Entry (ADDAJE) commands, respectively. In both cases, special values can also be used to define the job description parameter. Diving deeper into i5/OS work management is beyond this article's scope, but I have collected a number of links providing useful information for learning more about this topic:
This APIs by Example includes the following sources:
CBX161 -- Work with Referenced Job Descriptions - CCP
CBX161E -- Work with Referenced Job Descriptions - UIM Exit
CBX161H -- Work with Referenced Job Descriptions - Help
CBX161P -- Work with Referenced Job Descriptions - Panel Group
CBX161X -- Work with Referenced Job Descriptions
CBX161M -- Work with Referenced Job Descriptions - Build Command
To create all these objects, compile and run CBX161M. Compilation instructions are in the source headers, as usual.
Q: I'm new to ILE, and I'm not sure whether I bound my program to a *MODULE or to a *SRVPGM. How can I find out how it was bound to verify that I did it correctly?
A: Whenever you're new to something, it's always good to have a way to check the results of what you did, to ensure that it all worked the way you expected it to. ILE is no different.
The Display Program (DSPPGM) command tells you which modules were copied into your program, as well as which service programs your program references. For example:
DSPPGM PGM(mylib/mypgm)
The first screen is helpful for checking that your program has the correct activation group, as well as adopted authority settings, and so forth. It looks like this:
These are the modules that you listed in the MODULE keyword of the Create Program (CRTPGM) command, or that were included as *MODULE type entries in a binding directory. If you used a binding directory, only the modules actually used are listed here.
If you like, you can key the number 5 next to each module to view more information about it. This option tells you the source file and member from which the module was created, the date and time that source member was last modified, and lots of other stuff.
When you're done viewing the details of the module(s), you're returned to the screen where it listed them. If you hit the Enter key once again, you see the service programs referenced. Here's what that screen looks like:
Display Program Information
Display 4 of 7
Program . . . . . . . : MYPGM Library . . . . . . . : MYLIB
Owner . . . . . . . . : GOODGUYS
Program attribute . . : RPGLE
Detail . . . . . . . . : *SRVPGM
Type options, press Enter.
5=Display
Service
Opt Program Library Signature
QRNXIE QSYS D8D9D5E7C9C540404040404040404040
QRNXUTIL QSYS D8D9D5E7E4E3C9D34040404040404040
QLEAWI QSYS 44F70FABA08585397BDF0CF195F82EC1
UTILR4 *LIBL E4E3C9D3D9F4E2E3C1E3C9C340404040
Bottom
F3=Exit F4=Prompt F11=Display character signature F12=Cancel F17=Top
F18=Bottom
The first three service programs listed (the ones in library QSYS) are automatically bound to all ILE RPG programs. I didn't have to specify them in a binding directory or on the CRTPGM statement. They're always included automatically because they contain routines that the RPG runtime environment needs to run an RPG program.
The last one (UTILR4) is one of my own service programs. Because I found it here in the service programs section and not on the modules screen, I know that I'm calling the service program's routines instead of calling its modules directly. That's important, because I don't want to have to rebind all my programs if I make a change to the UTILR4 service program.
The DSPPGM command makes verifying that you created your *PGM object with the right parameters easy. When you want to check a *SRVPGM object to see which modules or other service programs it references, you can use the Display Service Program (DSPSRVPGM) command. It works almost exactly the same as DSPPGM, except that it shows the details of a *SRVPGM object instead of a *PGM object.
When you want to control how long journal receivers are available online, you will want to "age" the receivers. For example, if you want to keep five days' worth of transactions online, you can either manually delete the old receivers or run the command presented this month.
The Remove Journal Receivers (RMVJRNRCV) command lets you age the receivers and optionally connect the journal to a new receiver.
You can run this command against all your journals, including QAUDJRN, to perform an intelligent deletion of old receivers.
The command performs a clean-up process against the specified journal's receiver directory. You can specify the number of journal receivers to retain, the number of days (since detachment), or a combination of both. The force parameter controls whether the journal receivers should be saved to be eligible for deletion and, for remote journals, whether replication should occur. Optionally, you can have the CHGJRN command run to change the journal receiver (before directory clean up). I've also included the Sequence option so you can ensure that the journal entry numbering is continued, regardless of the current default value of the CHGJRN command.
For more details about command parameters and command usage, refer to the help panel group.
The following source code is included. As always, check the source code headers for compile instructions and additional documentation.
Journals are used by i5/OS for many purposes, such as
recording before and after images of database record inserts, changes, and deletions
recording security-related events like authority failures, invalid sign-ons, changes to system values, and deletion of objects
recording user-defined events
If you are curious about how many journals exist on your system, you can run the command WRKJRN *ALL/*ALL. There are a multitude of journals; most are used for recording database changes. IBM supplies many of the journals, and others are user created. One of the issues that you run into with journals is that the associated journal receivers can often require significant disk space. The journal receiver is actually the storage area for the data collected through the journal.
How Big Are My Journal Receivers?
To display all your current journal receivers and to get a listing of the size of each receiver, you can use the following command:
Or you can choose the OUTFILE option and place the output in a database file. You can then use a query tool to list the receiver name (ODOBNM), the library name (ODLBNM), and the receiver size in bytes (ODOBSZ). I think if you add up the size of all your journal receivers, you'll be surprised at the amount of disk space used to hold all journaled data. Some of you will be appalled.
You will want to delete the journal receivers that are no longer needed. To identify those that are not needed, look at the detach date and whether the receiver has been saved. You determine how many days of receiver data you need by considering your requirements for reporting, freeing disk space, and forensic research on the receiver data.
How to Call an API Without Worrying About the 64 KB Limit
Q: I want to return information about the indices built over a physical file. I'm using the Retrieve Member Description (QUSRMBRD) API to do that. One of our files has more than 70 logical files built over it, and each index needs 2,176 bytes of space. If my math is correct, that means I need 217,600 bytes! Is there a good way of overcoming RPG's 64 KB limitation? In the future, I want to be ready to handle even more indices, should they be needed!
A: The QUSRMBRD API, like many APIs, can tell you how much space it needs to return all its results. Rather than use a variable whose size must be known at compile-time, I suggest using dynamic memory allocation. That way, you can ask the API how much space it needs and then tell the operating system that you need exactly that much memory. Using this technique, you won't have to worry about RPG's 64 KB limitation.
The QUSRMBRD API when called with format MBRD0400 returns an array of information about the indices of a file. At the start of MBRD0400, there's information about how much space the API needs to return a complete array. The start of the format looks like this:
D MBRD0400 ds qualified
D based(p_RcvVar)
D BytesRtn 10I 0
D BytesAvail 10I 0
D Count 10I 0
D Offset 10I 0
As you can see, I based this data structure on a pointer. I ask the system to allocate enough memory to store this minimal data structure, and I pass that to the API. Of course, the API can't fit any indices in the preceding data structure, but it fills in the BytesAvail variable, and that variable tells me how much memory I need if I want the whole thing.
The first time through the loop, nothing has yet been allocated to p_RcvVar, so it is set to *NULL. When this happens, I use the %ALLOC built-in function (BIF) to ask the operating system for enough memory for the minimal data structure.
The second time through the loop, I release the memory that the operating system previously provided, and I ask for enough memory to get everything the API has to offer and call the API again.
In almost all cases, the program runs through the loop only twice. If someone manages to add a new index between the time I call %ALLOC and the time I call the API, I end up looping a third time to expand the memory again. In the end, though, I get the whole thing.
After you do that, you can use the same pointer logic that you typically use with offsets provided by APIs to loop through the returned data and do something with it. For example:
D InxDS DS Based(p_InxDS)
D qualified
D LibNam 258A Varying
D FilNam 258A Varying
D MbrNam 258A Varying
D CstTyp 11A
D 9A
D InxVld 1A
D InxHld 1A
D 6A
D CrtDTM 14A
D RBldDTM 14A
D UseDTM 14A
D SttDTM 14A
D UseCnt 20I 0
D SttCnt 20I 0
D Stt2Cnt 20I 0
D Keys 20I 0
D Size 20I 0
D Key1Unq 20I 0
D Key2Unq 20I 0
D Key3Unq 20I 0
D Key4Unq 20I 0
D RBldSec 10I 0
D DlyKeys 10I 0
D OvFlCnt 10I 0
D CdeSiz 10I 0
D LFRdRqs 20I 0
D PFRdRqs 20I 0
D 56A
D Sparse 1A
D DrvKey 1A
D Partnd 1A
D Maint 1A
D Recvry 1A
D Type 1A
D Unique 1A
D SrtSeq 1A
D SrtLib 10A
D SrtNam 10A
D SrtLang 3A
D SrtWgt 1A
D PagSiz 10I 0
D KeyLen 10I 0
D KeyCnt 10I 0
D 82A
D KeyLst 1024A Varying
.
.
for ix = 1 to MBRD0400.Count;
p_InxDS = p_RcvVar + MBRD0400.Offset +
(ix-1) * %size(InxDS);
// do something with the data in the InxDS
// data structure here.
endfor;
dealloc p_RcvVar;
Don't forget to use the DEALLOC opcode at the end of the program to return the allocated memory to the system. (If you forget, it won't be released until the activation group ends.)
Q: I'm writing an RPG program that has a numeric field defined as "5P 2". If it contains a value such as 3.00, I want to move it to a character field and display it without trailing zeroes. However, if the decimal has a value such as 3.01, I want to display it as is. How can I do this?
A: There isn't an edit code or edit word that strips trailing zeroes, so you have to write a bit of program logic.
The basic premise of this code is to check the variable to see whether anything is in the decimal places. If it is, move them to the numeric field. If not, strip them before you move them. The following code works in V5R1 or later:
D mynum s 5 2
D char s 7A
.
.
if %dec(mynum:3:0) = mynum;
char = %char(%dec(mynum:3:0));
else;
char = %char(mynum);
endif;
The %DEC() built-in function (BIF) is used to convert the number to a 3,0. In other words, it's the same field, but without the two decimal places. If it still has the same value after the decimal places have been stripped, you know that those decimal places were zero. Therefore, you can format this 3,0 field into the character variable.
If stripping the decimal places causes the value to be different, then a value must've been in those decimal places, so they're kept in when formatting the string