bespiegelingen over Verkavelingsvlaams en kuddegedrag
19-03-2009
De kuddetheorie - een simulatie
De kuddetheorie kan beschreven worden worden in niet meer dan negen regeltjes programmacode. Omdat we daarbij een goede random-numbergenerator nodig hebben, is onze keuze gevallen op het statistische pakket R (gratis downloadbaar via: www.r-project.org).
Het programmaatje dat de hele kuddetheorie in één formule samenvat - en dat er dan ook de formele neerslag van is, waarop in het vorige bericht gealludeerd werd - heet duolog:
duolog <- function(sym,mul=1,sim=10000) { len <- length(sym) out <- matrix(1,nrow=len,ncol=2,dimnames=list(sym,c("ann","bob"))) while ((((sum(out)/2)-len)/mul)<sim) { out[,2] <- out[,2]+mul*rmultinom(1,1,(out[,1]/sum(out[,1]))) out[,1] <- out[,1]+mul*rmultinom(1,1,(out[,2]/sum(out[,2]))) } out }
Het laat twee sprekers, genaamd: 'Ann' en 'Bob', om beurten een bepaald symbool uiten, waarbij zoals gezegd de corresponderende kans van het geuite symbool bij de andere spreker verhoudingsgewijs lichtjes stijgt. In het programma is de precieze lijst van symbolen (in technisch jargon heet dit het 'alfabet') variabel gelaten - dit is het argument sym in het programma - maar voor onze bespreking stellen we die gelijk aan het rijtje uit het vorige bericht: "a", "b", "c", "d" en "e".
sym <- c("a","b","c","d","e")
A priori willen we van zo weinig mogelijk aannames uitgaan, en daarom stipuleren we dat aan het begin - voordat er nog maar één uiting plaatsgevonden heeft - de waarschijnlijkheden van de symbolen voor beide sprekers uniform verdeeld zijn, wat wil zeggen dat elk symbool bij elke spreker aanvankelijk 1/5 kans heeft om geuit te worden. Daarna laten we beurtelings Ann een symbool aan Bob communiceren, en Bob aan Ann, waarbij de ontvanger telkens zijn/haar kansverdeling met een bepaalde kwantiteit aanpast - die kwantiteit wordt gegeven door het argument mul, en is in principe eveneens vrij te kiezen, hoewel we die standaard op 1 gezet hebben (wat te maken heeft met een eigenaardigheid van het R-pakket zelf: in R wordt bij een kansverdeling de noemer van de waarschijnlijkheden automatisch berekend als de som van de tellers, zodat het niet per se nodig is om een noemer te specificeren; enkel de tellers zijn al voldoende, en daar wordt de mul-kwantiteit meer bepaald bij opgeteld). Dat heen en weer verzenden laten we zich een aantal malen herhalen - wat we opnieuw zelf kunnen bepalen: dit is het argument sim - waarna we de uiteindelijke frequentieverdeling voor beide sprekers in een tabel verzamelen.
Na één enkele uitvoering van het programma met de default opgegeven 10000 iteraties verkrijgen we de volgende cijfers:
ann bob a 464 472 b 2933 2957 c 3703 3649 d 1082 1088 e 1823 1839
Relatief gezien wordt dat (beide kolommen delen door hun respectieve kolomtotalen):
ann bob a 0.05 0.05 b 0.29 0.30 c 0.37 0.36 d 0.11 0.11 e 0.18 0.18
Zoals ook de figuur in bijlage visualiseert, hebben beide sprekers inderdaad dezelfde (niet-uniforme) frequentieverdeling voor de vijf symbolen "a", "b", "c", "d" en "e".
Op de koop toe kan het laatste restje twijfel de kop worden ingedrukt door middel van de geijkte test voor de gelijkheid van frequentieverdelingen: de Chikwadraattoets. Toegepast op de tabel met absolute frequenties geeft die de volgende uitkomst:
X-squared = 0.6493, df = 4, p-value = 0.9574
Dit is toch een opmerkelijk resultaat: zelfs met onze hoge frequenties (en zoals bekend is chikwadraattoets daar gevoelig voor: de teststatistiek neigt sterker naar significantie naarmate het totale aantal observaties toeneemt) kan de nulhypothese van homogeniteit niet verworpen worden.
De centrale gedachte achter de kuddetheorie kan in één zin samengevat worden, en luidt als volgt:
Wij zijn er instinctief toe geneigd om elkaars gedrag over te nemen.
Laat dit een nog weinig opzienbarende stelling zijn - alhoewel het in sommige kringen toch al menig discussie verhitten zou, en dat gaat het vooral over filosofisch aangelegde menswetenschappers - het bijzondere aan de kuddetheorie is de precieze, lees: mathematische, uitwerking ervan. Voor het eerst wordt kuddegedrag namelijk in termen van wiskundige formules beschreven. Omdat de kuddetheorie in de eerste plaats bedoeld is om taalgebruik te verklaren blijven we daarbij in taalkundige sfeer.
Stel twee personen, A en B, die met elkaar communiceren, en daarbij de keuze hebben - we houden het even eenvoudig - uit bijvoorbeeld vijf symbolen, te weten: "a", "b", "c", "d" en "e". Elke spreker uit daarbij zijn symbolen met een bepaalde kansverdeling. Voor spreker A is de waarschijnlijkheid van symbool "a": paA, van "b": pbA, "c": pcA, "d": pdA, en "e": peA. Voor spreker B is het analoog: "a": paB, "b": pbB, "c": pcB, "d": pdB, en "e": peB (en aangezien het hier om waarschijnlijkheden gaat, geldt natuurlijk - we vermelden het maar voor de zekerheid - zowel paA + pbA + pcA + pdA + peA = 1 als paB + pbB + pcB + pdB + peB = 1). Het cruciale punt is nu dat telkens als één van de sprekers een bepaald symbool uit, bij de andere spreker de corresponderende waarschijnlijkheid een ietsje toeneemt, terwijl de waarschijnlijkheden voor de vier andere symbolen verhoudingsgewijs lichtjes afnemen. Als bijvoorbeeld spreker A het symbool "c" uit, dan zal bij B de kans pcB een beetje stijgen, terwijl evenredig daarmee paB, pbB, pdB en peB dan weer ietsjes zullen dalen.
Dat is kort de kuddetheorie in woorden. Nog duidelijker zou evenwel zijn als één en ander concreet geformaliseerd werd - in de vorm van een computersimulatie, bijvoorbeeld.




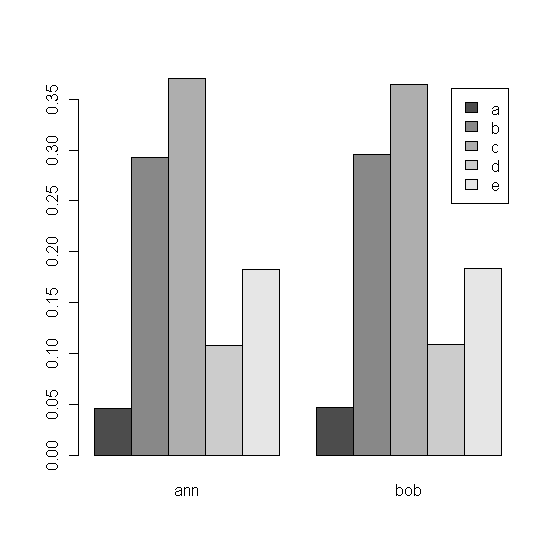{kind=link}